- 从零开始构建一个小程序
- 小程序测试、上线
- 小程序开发、上线过程中常见问题
- 使用第三方快速构建小程序。
- 使用wepy构建小程序
- 最近一次上线,由于架构变动过大以及测试不严谨导致上线后问题多多又回滚了;导致服务前后工停了7个小时。
- 另外一个是一直以来存在的问题:开发出来的功能bug率奇高无比,且总是遗漏了一些需求;导致目标一拖再拖。
- Logs工具类
- 核心接口Log:封装是封装了所有日志输出方法
- 核心接口LogAdapter:是日志适配器接口,只有一个方法:getLogger ,用来获取对应的日志输出器
- 第一 总记录在3000万条(基本上)主流企业的数量,
- 第二 该库要能方便的通过各种维度查询,统计,分析。 想了两天,并且开会讨论后决定使用mongodb加elasticsearch的方式:
- mongodb负责数据存储。
- elasticsearch负责建索引。 于是查了各种资料,暂时决定,mongodb保存记录的时候,通过一些同步工具自动将记录在es中建立索引。 环境搭建工作分三步:
- 搭建es集群环境(这个环境公司已经有了,所以不用做这方面工作)
- 搭建mongodb集群环境
- 通过一些外部工具将mongodb数据同步到es中,看中了两个工具,一个是elasticsearch-river-mongodb,一个是Mongodb Connector
- Http是入口类,直接调用get方法传入url,即可获得Response对象,
- 接下来是一个比较核心的对象Sender类,该类用于发送请求,根据请求方式具体有GetSender和PostSender两个子类。
- Sender类方法的主要功能是根据传入的参数构造Request请求,并且打开连接(OpenConnection),底层是调用Url的openConnection。
- 然后调用send方法返回Response对象,send方法由子类GetSender和PostSender具体实现。上面例子中调用的是GetSender类的send方法。
- send方法中调用三个方法openConnection(打开连接),setupRequestHeader(设置请求头信息),createResponse(获取Reponse对象)。
- 其实这三个方法都是调用父类Sender中封装的方法。后面会介绍其实PostSender类的send方法中也是这么调用的,只不过传递参数的时候有一些特殊处理。
-
前者用来对已有的mapl结构进行重构。包括添加,删除,读取指定路径的值 比如针对下面一个mapl结构的数据
{'user':[{'name':'jk', 'age':12},{'name':'nutz', 'age':5}]} -
我们要在这个路径:user[0].test 增加值”hello”使其变为
{'user':[{'name':'jk', 'age':12,'test':'hello'},{'name':'nutz', 'age':5}]} -
而MaplMerge 主要用来将多个mapl结构数据合并起来,该类只有一个接口:mergeItems(Object… objs)
- maplistToObj(Object maplist, Type type)
- maplistToT(Object maplist, Class
clz) - ObjConvertImpl,将maplist数据转换为指定的java对象
- ObjCompileImpl,将java对象转换为maplist结构。
- MaplRebuild,对maplist结构进行修改操作,可以修改,删除制定路径的值,可以合并多个maplist为一个。
- MaplMerge, 将多个maplist合并为一个。
- FilterConvertImpl,针对maplist进行过滤,可以根据路径去掉不想要的路径,或者仅保留制定路径的值。
- StructureConvert,可以根据模板将maplist结构进行转换,比如将{“name”:”华为”,”date”:”1992/01/02”}转换为:{“entName”,”华为”,”esDate”:”1992/01/02”}
- json的注解
- json的格式化
- json异常处理
- Json类将java对象和字符串进行互相转换。
- 定义了json的注解。包括:Jsonield,JsonIgnore,ToJson
- 针对json的输出进行了一些格式的控制,涉及类包括:JsonFormat
- 异常处理:JsonException
- 其他定义的一些接口和具体工具类,这里不一一列觉。
- 该模块的结构图如下所示:
- Json 工具包
- Mapl结构
- 表达式引擎
- 在做类似信用评级的项目时候用到类似的东西了,暂时用的是Beanshell,可以借此机会看看类似引擎如何实现的。也能更好的使用
- Http客户端
- 最近在做数据采集的项目,httpclient用的七零八落的,需要借此整理下了。
- 看完这个,再去好好看看Apache 的httpclient
- 甜java java工具包,这个分为好几个子模块,具体看得时候再列具体计划。
- Nutz.Dao
- IOC 和AOP
- Nutz.MVC
- 图像处理
- 与其他第三方框架的集成。
- Redis 集群是一个提供在多个Redis间节点间共享数据的程序集.
- Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
- Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令.
- Redis 集群的优势:
-自动分割数据到不同的节点上.
- 整个集群的部分节点失败或者不可达的情况下能够继续处理命令.
记录一次数据库磁盘整理工作过程 03 Nov 2023
负责的的一个系统中有一张大表,目前来看已经260GB,其实表里的数据因为合规的需要已经删除一半左右。但是mysql的机制问题,虽然数据库删除了,但是这部分空间并没有被回收。目前磁盘可用只剩下20%,趁着最近一次系统暂停升级打算对数据库磁盘进行回收
查看文章...
春节为什么回家过年 06 Jan 2023
又到了一年一度的春节时间。
老婆跟我微信上聊天,试图说服我春节不回家过年。让我不得不仔细想想春节回家过年的意义是什么
查看文章...
升级mysql驱动导致的异常:validateconnection false 27 Oct 2022
最近客户扫描服务器漏洞,要求升级mysql的java驱动包,想着不是什么大师,顺手升级了下,没想到升级后报错: java.sql.SQLException: validateConnection false。
查看文章...
Fastjson升级到2.x 29 May 2022
记录升级fastjson从1.x升级到2.x后的相关问题和内容
查看文章...
升级jxls相关问题 04 Mar 2022
记录升级jxls后的相关问题和内容
查看文章...
Html5上传视频和后台视频压缩 18 Mar 2020
最近项目中遇到这种需求:要求用户在手机端HTML5拍摄视频并上传,后台管理员读取视频进行审核。由于之前没有处理过视频相关内容,遇到了不少坑。
查看文章...
使用visual studio code做java开发 入门篇 10 Oct 2019
最近在尝试用vscode做java开发,主要是想把家里的4G内存的mac本本用起来,使用IDEA打开有点慢,所以打算用vscode做开发。下面文章主要记录使用vscode做java开发过程中主要涉及到的插件,资源,配置;并不会一步步的教你入门;毕竟网上资料太多了。
本文章会不定时更新
查看文章...
Easymock数据模拟服务 18 Sep 2019
最近做项目越来越多的用上Vue.js,项目前后端分离也成了趋势。在做前端开发中发现一个不错的工具:Easy Mock,这是一个快速生成模拟数据的在线服务,尤其配合swagger(后端同学应该很熟悉啦)用起来非常快捷方便。
查看文章...
使用arthas进行线上java应用诊断 06 Sep 2019
最近发现一个挺好用的工具:alibaba出的Arthas。这是一个java应用线上诊断工具。如果你之前用过Btrace,那么理解起来Arthas就不难。这两个都是java线上应用诊断工具。比如你想了解当前执行应用的内存占用,线程情况,具体参数值等信息,无需麻烦的打日志,上线就可以用上面的工具轻轻松松解决问题。
之前也了解过Btrace,但是鉴于用起来太麻烦,一直不喜欢用。这次发现了Arthas,用起来简直不要太方便。这两个工具的功能类似,要说区别嘛举个例子对比就是:你把Btrace比作飞刀,如果你是李寻欢,那么凭借这把飞到什么妖魔鬼怪你都可以干掉。而Arthas理解为AK-47。拿着这玩意,我们普通人也可以横扫天下了😄。
查看文章...
将一个项目提交到多个git仓库 27 Aug 2019
最近在维护一个开源项目,想同时在github和gitee上做版本管理,gitee上有个功能可以把github上的项目同步过来。 这个功能挺好用的,我只要每次将项目更新推送到github,然后在gitee上点击刷新就可以将最新的代码从github同步过来。
但是,看了一眼gitee上的说明,如果是从github同步过来的项目,就没办法得到网站的优先推荐,也不能选评最有价值开源项目等。虽然这也没什么大不了,但是辛辛苦苦维护要给项目,总是希望能被好好推广让更多人知道。
于是就上网找了找看能否同时将一个项目推送到github和gitee,来代替通过同步刷新的方式从github同步到gitee的方式。
查看文章...
Spring boot之数据校验validator 01 Aug 2019
在web项目中经常要对用户输入的信息做校验。通常的做法是在前端使用js做初步的验证,
然后在后端再做进一步校验。本文会简单介绍在Spring Boot项目中使用hibernate-validator做后端数据校验的做法。
查看文章...
Spring boot项目中封装公共的service和repository 29 Jun 2019
在SpringBoot项目中我们经常会提取一些公共的方法封装起来,放到父类中;子类继承父类后复用这些方法,如果自己有特殊需要再写自己特有的方法。 一般的web项目核心功能离不开对数据库数据的增删改查操作,因此封装公共的service和repository是很有必要的。
下面针对我们一个项目的封装过程做个总结
查看文章...
Spring boot之数据审计jpaauditing 29 May 2019
通常我们都有这样的需求:我需要知道数据库中的数据是由谁创建,什么时候创建,最后一次修改时间是什么时候,最后一次修改人是谁。
在Spring jpa中可以通过在实体bean的属性或者方法上添加以下注解来实现上述需求@CreatedDate、@CreatedBy、@LastModifiedDate、@LastModifiedBy。
查看文章...
一直在更新的超全的免费电子书列表 22 Aug 2018
今天在github上发现一个超级全面的免费电子书列表,而且一直在更新,各个国家语言的都有,
这里仅列出中文:https://github.com/EbookFoundation/free-programming-books/blob/master/free-programming-books-zh.md
和英文:
查看文章...
Pdf在线合并上线啦 12 Jul 2018
[更新:服务器资源问题已下线] pdf merge online 在线pdf合并上线啦 做这个网站的起源是之前在开一个网络课程,每节课都有一个pdf课件。想合并成一个看起来方便些, 于是网上找一些在线的合并pdf工具,没有特别好用的,只好自己撸一个 戳这里试用http://pdfmerge.enilu.cn
查看文章...
Hiberate lazy加载和fastjson循环引用检测导致列表查询的问题 03 Jul 2018
做分页查询的时候,发现外键关联的数据查询不出来,而且比较诡异的时候一个列表中,前面记录关联的记录可以正常出来,后面记录的关联数据出不来,debug发现返回的数据后面的出现:{“$ref”:”$.rows[2]”} 的情况
查看文章...
Guns Lite基于spring boot的后台管理系统 05 Apr 2018
年初公司计划要上一个产品,而且是要在两周内上线(由于之前已经开发、运营过一个类似的产品,所以这次要求先将核心功能上线;当然最后没有那么快上线,这是后话)。 由于这个系统比较复杂,所以我们和以前一样计划将服务拆分,包括后台管理、微信端,api层,消息服务,调度任务等若干服务。领导既然发话了,无论计划看上去多么不靠谱,撸起袖子也得干。
查看文章...
小程序开发入坑之旅 26 Jan 2018
本篇文章并不会完全从开发的角度描述如何开发一个小程序,毕竟官方的文档已经很齐全了 戳这里看官方文档:https://mp.weixin.qq.com/debug/wxadoc/dev/。
本文会从如何快速上线一个小程序的角度来进行阐述。主要分文以下几个方面。
查看文章...
2017年终总结 23 Jan 2018
2018年春节马上就要来临了,按照惯例,春节几乎是上一年年终总结的最后撰写期限。趁着春节大限未到,总结下自己的2017年。
查看文章...
Kafka常用命令 30 Mar 2017
记录下常用的kafka命令
查看文章...
Maven构建问题解决 27 Mar 2017
今天发现jenkins构建失败,错误内容如下:
[ERROR] Failed to execute goal on project snow-payment-provider: Could not resolve dependencies for project .................., mysql:mysql-connector-java:jar:5.1.24 (compile), org.bouncycastle:bcmail-jdk15:jar:1.46 (compile)]: Failed to read artifact descriptor for org.jetbrains:annotations-java5:jar:RELEASE: Failed to resolve version for org.jetbrains:annotations-java5:jar:RELEASE: Could not find metadata org.jetbrains:annotations-java5/maven-metadata.xml in local (/data/maven/maven3.0.5/repo) -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :snow-payment-provider
查看文章...
关于初创公司开发人员的效率和质量问题的思考 05 Mar 2017
最近公司发生了一些事情,引发了自己的一些思考,这两天复盘了一下,总结一下问题。 先说问题(事故),主要问题有两个,
针对前一个问题我想说下小公司的运维问题和上线流程。针对后一个问题,我想说说对开发流程方面的看法。
查看文章...
Spring @responsebody 中文乱码 20 Feb 2017
前端页面使用ajax请求后台,后台使用SpringMVC接收请求,发现action返回中文的时候总是乱码。
查看文章...
Windows本地运行jekyll网站 25 Jan 2017
用github pages做个人站点有一段时间了,用的是jekyll的一个模版jekyll-bootstrap。 之前一直没有在本地运行起来,最近出差晚上实在无聊,就在本地跑起来咯。
先说参考文档:http://jekyll-windows.juthilo.com/。 照着上面步骤做,基本没什么问题,我下面除了再重复下文档中的步骤以外,再记录下期间遇到的坑。
查看文章...
Spring aop例子 21 Jan 2017
使用spring可以很方便的编写aop程序
查看文章...
使用github搭建个人的maven仓库 09 Jan 2017
发现一个github很有用的方法,使用github搭建个人的maven仓库 原文地址
下面记录下自己的搭建过程 ,备忘下。
查看文章...
Nutz源码阅读之日志的实现 16 Oct 2016
正如nutz官方所说,nutz并没有实现了日志功能,而只是适配日志。那么,本篇就来看看nutz是如何来适配日志的。
先来看下nutz log的整体结构
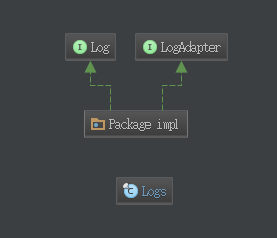
主要包括三部分内容:
查看文章...
(转)我脑海中的优秀技术团队 30 Jul 2016
这是一篇未作任何加工的转载文章点击查看原文
摘要:我们都明白这样的道理:一根筷子很容易被折断,但是一把筷子就不容易被折断。这其实告诉我们团队的重要性,因为一个人的力量终究是有限的,不可能完成一个团队的工作。而对于技术团队而言,怎样才算的上是优秀的技术团队呢?什么样的技术团队才能既完美地完成任务又让团队成员都得以成长呢?
文中的“我”,其实不是一个单纯的角色,它可能会包含多层含义,不管是我作为一个团队的管理者,还是我作为一名技术团队的普通员工,都会对自己的团队有一些期许,一些定义,一些要求,而这就是今天我们要谈论的话题。希望这些思考能够对管理者或者求职者有些帮助。
查看文章...
Web网站性能调优 动态和静态资源分离 27 Jul 2016
最近工作不是特别忙,加上公司同事一直反映系统访问比较卡。打算把性能优化这块一点一点做起来。
今天先说动态资源和静态资源分离
查看文章...
Es1.4.4升级到es2.3.4填坑之旅 18 Jul 2016
系统之前用的是es1.4.4;es的作者很勤奋啊,不到两年,版本变成2.3.4了;es版本落后太多,享受不到最新的特性。打算近期升级一下。 升级过程断断续续花3天。
记录下填坑过程
查看文章...
开发环境相关软件启动命令备忘 08 Jul 2016
测试环境有时候会需要重启,记录下一些环境的启动命令,不然总是忘了。难道年纪大了,记性不好?!?!? 另外还用了其他工具系统(jenkins,SonarQube ),后续慢慢补齐了。
redmine
启动命令,进入服务器的/home/redmine/目录,运行命令:
nohup ruby script/rails server mongrel -e production -p 3000 -d &
也可以运行将上述命令写入到脚本(start.sh)里,然后运行脚本:
./start.sh
##gitlab 启动命令,进入服务器切换git账户,运行命令:
/etc/init.d/gitlab start
#也可以运行:
service gitlab start
查看文章...
Nutz源码阅读之lang包之反射 02 Jul 2016
关于反射,Nutz中提供了Mirror类。这里是该类的帮助文档Mirror帮助文档。 看过这个文档后,使用Mirror是没有什么问题了。
查看文章...
夜间随想 28 Jun 2016
我去迪士尼是因为别人也去迪士尼,并不是因为我心中有个梦想乐园;
我去创业是因为大家都在创业,并不是因为我觉得创业能实现自己的人生价值;
我健身是因为大家都在健身,并不是因为我热爱运动和汗水直流的感觉;
我不站出来说话是因为别人也不站出来说话,并不代表我对这个社会没有意见。
查看文章...
Nutz源码阅读之lang包之io操作 18 Jun 2016
本文主要说说IO处理工具Streams和文件处理工具类Files。 这里事先说明下,以前和以后的文章里面,粘贴的代码主要是为了说明实现逻辑登,我会把一些异常处理,等无关逻辑的代码删除掉,避免文章出现大段大段的代码。
查看文章...
Mongodb集群安装配置 15 Jun 2016
因业务需要,需要在centos安装一个mongodb集群做测试,折腾了一天,把坑都记下来,免得忘了。 mongodb集群搭建有三种方式:Replica Set / Sharding / Master-Slaver。本文使用Replica Set 方式。 Replica Set 就是集群当中包含了多份数据,保证主节点挂掉了,备节点能继续提供数据服务, 提供的前提就是数据需要和主节点一致,结构图如下:

Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。 客户端同时连接主节点与备节点,不连接仲裁节点。
默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务, 这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做Read Preference Modes, 同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点, 所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。 本问就是用这种方式搭建mongodb集群
查看文章...
Nutz源码阅读之lang包之基本类型工具 04 Jun 2016
上一篇文章针对lang包中基本类型中的字符串工具类Strings做了阅读,这次来完结剩下的两个:Nums,Times,
查看文章...
Nutz源码阅读之lan包之基本类型工具(strings) 03 Jun 2016
这篇文章说下,lang包中基本类型相关的工具类,说基本类型其实有点不太准确,主要是针对字符串(Strings),数字(Nums), 日期(Times)的工具类。 下面一个一个类来看了,其实鄙人java基础很不扎实,这次趁着阅读基础的工具类的机会也好好复习巩固下基础。有说的不对的地方,欢迎批评指正。辣么,开始吧。
查看文章...
Mongodb入门 31 May 2016
下面是给同事做的mongodb入门培训资料,都是一些很简单的东西,目的就是对mongodb有个大致的概念
查看文章...
我是如何用centos做开发持续一年的(续) 27 May 2016
上一篇我是如何用centos做开发的持续一年的在简书上发表后, 有几个评论,大概意思是:感觉你什么都在windows虚拟机做了,要centos干嘛。
这个怪我,题目叫做“如何用centos做开发”,写的却都是如何在windows虚拟机里干非开发的事情。
这篇补上来,说说我在centos都做了什么。
查看文章...
Elasticsearch和mongodb数据同步 26 May 2016
公司产品部门最近出了个新需求,希望能将公司各种来源的数据根据企业唯一标识合并到一个大库中。理了一下具体需求,主要目标有两个:
查看文章...
初创公司可以多用云服务 24 May 2016
对于IT类的公司来说,人力成本是一项很大的成本。初创公司为什么要多用云服务?因为这样可以节约人力成本!
查看文章...
Java字符串的split和contains 20 May 2016
java中的字符串api String 类有封装了很多针对字符串操作的功能;不同的函数接收参数是不一样的,有的接收字符串参数,有的接收正则表达式参数。 之前用的时候没有注意这块,导致偶尔会出现一些问题。
查看文章...
我是如何用centos做开发持续一年的 19 May 2016
自从去年6,7月份将工作机切换到centos快一年了;今天细数以下这一年来遇到的体会。
查看文章...
怨天不如尤己 09 May 2016
眼看结婚已经块2年,快要奔三的人了,最近突然感觉压力好大;发现周围很多人也是这样;大概程序员奔三的时候大都有这种焦虑?!
查看文章...
Elasticsearch内存配置 26 Apr 2016
最近生产环境的es经常不稳定,用了一两天就开始报错,而测试环境的没有问题;甚是纳闷。看了错误日志如下:
org.elasticsearch.search.query.QueryPhaseExecutionException: [credit][2]: query[filtered(_all:北 _all:京)->cache(_type:entname)],from[12700000],size[100000]: Query Failed [Failed to execute main query]
at org.elasticsearch.search.query.QueryPhase.execute(QueryPhase.java:163)
at org.elasticsearch.search.SearchService.loadOrExecuteQueryPhase(SearchService.java:272)
at org.elasticsearch.search.SearchService.executeQueryPhase(SearchService.java:283)
at org.elasticsearch.search.action.SearchServiceTransportAction$5.call(SearchServiceTransportAction.java:231)
at org.elasticsearch.search.action.SearchServiceTransportAction$5.call(SearchServiceTransportAction.java:228)
at org.elasticsearch.search.action.SearchServiceTransportAction$23.run(SearchServiceTransportAction.java:559)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
刚开始以为是查询写的有问题,导致内存溢出呢。但是自己看了写日志产生日期,感觉不对劲啊,这个日志一直报着,而且大半夜也听不下来。
查看文章...
Nutz源码阅读之lan包初识 22 Mar 2016
lang包是nutz的工具包,俗话说:磨刀不误砍柴工 ,好到工具可以起到事半功倍的效果,同样,开发过程中,使用一个好的工具库,也能给开发带来不可忽视的便捷效果。今天先来大致认识下nutz的好工具:斧头,哦不,lang包。
查看文章...
周末刷街 20 Mar 2016
周六和周日在家实在无聊,代码看不进去啊,还有治么。
查看文章...
Java异常处理机制 13 Mar 2016
java异常天天用,但是你对他了解究竟有多少。俗话说学习不总结,等于没学习。(好吧,我承认是我说的)。
转自:点击查看
查看文章...
Nutz源码阅读之httpclient进阶 12 Mar 2016
上篇通过一个get请求大致弄明白了HttpClient的请求过程,和请求中使用到关键的几个类,这次来说说其他种类的请求,以及超时,上传文件,cookie的用法和实现。
查看文章...
Java线程池的用法 12 Mar 2016
jdk1.5之后自带了线程池功能,妈妈再也不用担心线程使用中遇到的各种坑了。
查看文章...
手动安装配置nginx 02 Mar 2016
相信做web开发的没有几个不熟悉nginx,所以这里就不介绍它,也不对他逆天的性能进行追捧了。 另外打算用yum安装nginx也不用看本文。yum可以方便的安装nginx没错,而且也能用的好好的。 但是如果你想在安装nginx过程中做更多自定义的工作,可以继续阅读下去。比如指定安装目录,指定要安装的插件等等。 [摘自百度百科]
查看文章...
迄今为止最快的gitlab发布 23 Feb 2016
gitlab8.5发布了,官方号称迄今为止最快的gitlab,下面是大致翻译一些关键点。
查看文章...
Nutz源码阅读之httpclient初识 02 Feb 2016
先来通过一个测试用例看看httpclient这个极简的库是如何工作的:
Response response = Http.get("http://nutztest.herokuapp.com/");
System.out.println(response.getContent());
这中间的调用链是:
Http.get(url)
---->Sender.create(Request.get(url)).send()
---------------------->Request.create(url, METHOD.GET, new HashMap<String, Object>())
------------------------------>return new Request().setMethod(method).setParams(params).setUrl(url).setHeader(header);
-------->new GetSender(request)
---------------------------------------->openConnection()
---------------------------------------->setupRequestHeader()
---------------------------------------->createResponse()
-------------------------------------------->status = conn.getResponseCode();
-------------------------------------------->detail = conn.getResponseMessage();
其实Httpclient的核心实现就是这些,其他主要是一些特殊情况的处理。 比如cookie的管理,post请求的处理,带文件的post请求处理。超时处理,代理的使用等等。
再次赞一下,nutz的测试用例挺的,看代码直接从测试用例一步步跟进去,可以很快的了解和掌握框架。强烈推荐。
这次就打算用测试用例来一步步阅读源码,这次概览顺便把get请求过了一遍,下次就以测试用例的post请求,超时来阅读学习。
查看文章...
如何有效利用百分之20的自由时间 30 Jan 2016
hacknews上发了一篇文章:如何有效利用20%的自由时间,看了觉得很有用;虽然作为天朝程序员,很少有所谓20%的自由时间,
但是个人人为,即使是对于正常的工作,也是有积极的借鉴意义的。下面是个人翻译的,水平不好,凑合看,e文好的直接看原文吧,
原文地址。
查看文章...
基于bootstrap的设计工具 30 Jan 2016
随着响应式网站的大热,bootstrap几乎成了事实上的标准,这不,hacker news站点一连介绍两个bootstrap相关工具:
一个bootstrap sutdio 用于开发基于bootstrap的网站;一个pingendo ,用于设计基于bootstrap的网站原型。不过要我看,用熟悉了后这两个工具都可以跨界来用。
这里不做详细介绍了。网上资料很多,最有效的了解方式,就是下载下来安装试用看看。
查看文章...
Facebook将关闭parse服务 29 Jan 2016
我们很艰难的做出了这个决定,即日起,我们将逐步关闭Parse服务。 Parse将在接下来的一年多里逐步退休。服务截止日期是2017年1月28日。 我们由衷的自豪通过这项服务帮助很多人构建伟大的移动应用,但是我们需要集中力量在我们资源优势的地方。
查看文章...
失去了什么,得到了什么 24 Jan 2016
周末因为房子的事情, 回了趟郑州,来回买的都是卧铺,睡一夜就到了。周五晚上回郑的火车,第二天早上到,10点多事情办完了。
查看文章...
Gitlab中redis no route to host 错误的解决 20 Jan 2016
公司的测试服务器(centos)做安全加固,折腾完后,gitlab代码版本管理系统用不了了,界面一直报500错误,通过,端口,进程,数据库配置都没有问题,诡异了。
查看文章...
Nutz源码阅读之表达式引擎之初识 17 Jan 2016
简介
el模块的包为:org.nutz.el;入口类是El,即org.nutz.el.El 该类封装了el的主要用法:eval
查看文章...
Sqlite入门 16 Jan 2016
简介
SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如 Tcl、C#、PHP、Java等,还有ODBC接口,同样比起Mysql、PostgreSQL这两款开源的世界著名数据库管理系统来讲,它的处理速度比他们都快。SQLite第一个Alpha版本诞生于2000年5月。 至2015年已经有15个年头,SQLite也迎来了一个版本 SQLite 3已经发布。 [摘自百度百科]
查看文章...
Nutz源码阅读之mapl结构之maplrebuild和maplmerge工具类 13 Jan 2016
如标题所示,这篇文章来说说两个工具类MaplRebuild和MapMerge。
查看文章...
Nutz源码阅读之mapl结构之mapl2object 11 Jan 2016
上篇阅读了nutz中Object2Mapl的源码,点击这里查看 这篇来说说Mapl2Object。Mapl中针对Mapl转换为Object提供了两个接口:
具体用法参考官方官方文档,这里不赘述。 maplist转换为真实的对象,主要使用了ObjConvertImpl类实现。 这篇文章主要来看这个类的实现。
查看文章...
Nutz源码阅读之mapl结构之object2mapl 05 Jan 2016
Mapl的使用方式参考官方文档,灰常详细了。这里不再赘述。 如图所示,Mapl有以下方法,可供使用
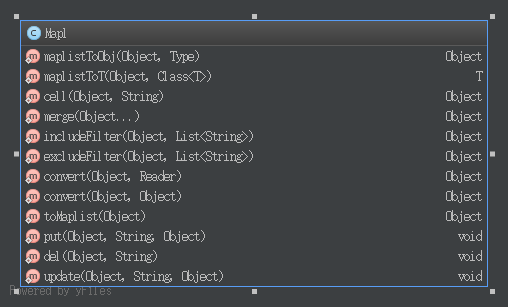
Mapl类中并没有实现具体的操作方法,分别调用的具体的工具类:
查看文章...
Nutz源码阅读之json系列二 03 Jan 2016
上篇主要阅读了Json类的方法,针对java对象和字符串之间的转换。 这篇主要针对json的一些工具类行的功能进行阅读说明, 包括:
以上。
查看文章...
Nutz源码阅读之json系列一 01 Jan 2016
json模块的包是:org.nutz.json,下文中涉及到的类名都是从该包路径说起。
json模块的大致功能包括以下几点:
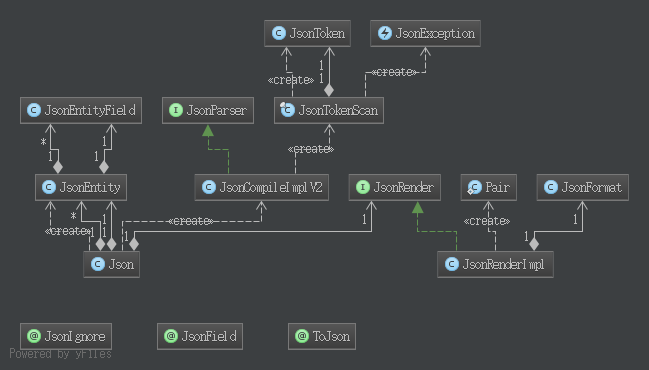
查看文章...
Hadoop2.6.0完全集群安装配置 27 Dec 2015
这个教程是按照hadoop2.6.0版本来整理的,2.x版本应该都适用,有什么问题欢迎留言。建议照着做的时候,各个软件版本尽量跟文档中一致,免得不必要的麻烦:
centos 6.5 64位版本
虚拟机:Virtualox4.3.3
jdk:java-1.7.0-openjdk-devel.x86_64 (无需下载直接用文档中的命令安装即可)
hadoop2.0.0
虚拟机中两台机器的网络都采用桥接模式
查看文章...
数据抓取之性能优化第一弹 24 Dec 2015
数据抓取本身流程很简单,但是当遇到网站的种类变多或者要采集的数据变多的时候,性能问题会称为数据抓取中要首要解决的问题。
这几天同事在测试采集数据的时候总是遇到反应很慢的情况。今晚趁着洗完澡脑子清醒,针对部分问题重构了下;做下记录。
查看文章...
Max_allowed_packet配置 21 Dec 2015
最近服务器经常报Packet for query is too large的错误,心想配置更改过了啊,怎么还会报错。
查看文章...
Nutz源码阅读 19 Dec 2015
老早就想就想写个nutz的系列阅读笔记,不知道nutz的点击这里,先列个阅读计划,从简单到复杂,免得自己没有动力了
阅读目录
查看文章...
数据抓取之反爬虫规则:csrf防御处理及异步请求处理 16 Dec 2015
同事在做数据抓取的时候,发现该提交的参数都提交了,但是返回的数据总是提醒“非法的请求或者超时”;我拿过来检查了半天也没见查出问题,无奈对比了下这个页面和另外一个页面的http头信息,端倪出来了,这页面http头信息多了个X-CSRF-Token的参数。这是什么东东,没见过,于是个谷歌科普了以下。
查看文章...
使用ikanalyzer进行分词 08 Dec 2015
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词语言包,它是以Lucene为应用主体,结合词典分词和文法分析算法的中文词组组件。 从3.0版本开始,IK发展为面向java的公用分词组件,独立Lucene项目,同时提供了对Lucene的默认优化实现。 IKAnalyzer实现了简单的分词歧义排除算法,标志着IK分词器从单独的词典分词想模拟语义化分词衍生。
查看文章...
西安之旅 04 Dec 2015
终于迎来了本年度的第二次旅游,之前一次去北戴河,那体验,说多了都是泪啊。这次出去总共3天,简单记录下这次出行的细节,以便老的时候和老婆相对实在无聊的时候可以拿出来杀时间,比瓜子好多了,不上火。
查看文章...
Redis.3.0.5集群安装详解 28 Nov 2015
之前写过一个redis的入门教程, 这次来用redis进行集群的安装配置。
Redis集群介绍
查看文章...
数据抓取之反爬虫规则:使用代理和http头信息 26 Nov 2015
之前说个数据抓取遇到的一个坎就是验证码,这次来说另外两个。我们知道web系统可以拿到客户请求信息,那么针对客户请求的频率,客户信息都会做限制。如果一个ip上的客户访问过于频繁,或者明显是用程序抓取,肯定是要禁止的。本文针对这两个问题说下解决方法。
查看文章...
数据抓取之反爬虫规则:验证码识别 24 Nov 2015
数据抓取过程中,验证码是一个必须面对的坎。总体来说验证码识别分两种,机器识别和人工识别,随着现在验证码越来越变态,要想机器识别验证码已经越来越难了,典型的入12306那种已经更改为图像识别,而不是简单文字识别了。
验证码识别技术有很多,这里仅总结自己在项目中用的的两种方式:
查看文章...
数据抓取之数据抓取流程 23 Nov 2015
公司的数据抓取系统也写了一阵子了,是时候总结下了,不然凭我的记性,过一段时间就忘的差不多了。打算写一个系列将其中踩过的坑都记录下来。暂时定一个目录,按照这个系列来写:
查看文章...
Gitbook使用手册 11 Sep 2015
现在写文档,记笔记,已经全面转到markdown了,相信很多小伙伴也一样,markdown的好处不用多说,单单两条,足以独步天下,编写简单(如果你是程序员的话就更觉得得心应手了),看起来漂亮(我说的是将它生成html后)
本文针对使用gitbook将markdown文档生成html做简单说明
查看文章...
虚拟机中centos磁盘扩容 09 Sep 2015
遇到了这样的情况,刚开始用虚拟机(virtualbox)安装两个centos环境,用了一段时间,磁盘不够了,需要扩容。具体操作过程中不是特别顺利,记录下,备忘
查看文章...
Linux防火墙配置 09 Sep 2015
简单的防火墙配置说明,没有更复杂的说明,复杂的自行谷歌
查看文章...
制作u盘并安装centos 07 Aug 2015
现在很少用光盘了,况且centos开源的,网上随便下载,所以安装的时候理所当然的想到用U盘安装,记录了具体步骤。
查看文章...
Piwik 安装配置 06 Aug 2015
本文章是我同事整理安装文档,觉得有用分享出来。Piwik是一个PHP和MySQL的开放源代码的Web统计软件. 它给你一些关于你的网站的实用统计报告,比如网页浏览人数, 访问最多的页面, 搜索引擎关键词等等… Piwik拥有众多不同功能的插件,你可以添加新的功能或是移除你不需要的功能,Piwik同样可以安装在你的服务器上面,数据就保存在你自己的服务器上面。你可以非常容易的插入统计图表到你的博客或是网站抑或是后台的控制面板中。安装完成后,你只需将一小段代码放到将要统计的网页中即可。
查看文章...
Kettle入门之spoon 01 Aug 2015
项目中有数据清洗的需求,自己对sql中的函数,存储过程,不是太熟悉,就使用kettle进行处理,
查看文章...
Elasticsearch 简单入门 04 Jul 2015
ElasticSearch是一个开源的分布式搜索引擎,具备高可靠性,支持非常多的企业级搜索用例。像Solr4一样,是基于Lucene构建的。支持时间时间索引和全文检索。官网:http://www.elasticsearch.org
查看文章...
Redis入门 09 May 2015
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
查看文章...
Mysql主从配置 08 May 2015
版本:mysql5.6
os:centos6.5
主服务器:(192.168.1.1),从服务器:(192.168.1.2)
查看文章...
Linux mysql数据目录迁移 07 May 2015
准备工作
版本:centos:6.5 64位 mysql:5.6
先说下mysql目录结构
centos6.5下安装mysql5.6后 mysql的数据目录,通过查看/etc/my.cnf
查看文章...
Centos配置bond ip冗余 07 Apr 2015
ipbbond是 centos 提供的ip冗余机制,这个机制帮助我们在ip资源上也实现了负载均衡。
查看文章...
Apache james快速部署 17 Nov 2014
Apache James是Aapache组织出品的开源邮件系统。可以用它快速搭建一个自己的邮件系统。
查看文章...
Python防止恶意抓取数据 25 Sep 2014
nginx默认会记录客户端访问服务端的日志,默认的目录位于:/var/logs/access.log;
业务需求:每小时读取access.log内容,统计每个ipd访问系统次数,如果超过指定次数,则将该ip加入到防火墙中,以便禁止其继续访问(后续可以考虑不是禁止其访问服务,而是重定向到指定的页面)。这样避免别人恶意从自己网站上抓取数据
查看文章...
简单的桌面搜索器 31 Jul 2014
需求,做一个桌面搜索小工具,将制定的目录下的文件,生成索引,提供一个搜索界面,输入关键字,在内容里搜索匹配的文件,列出文件信息:
查看文章...
5分钟看懂bson协议 29 Jul 2014
NOSQL从10年开始已经发展了4年了。其中最火的Mongodb也被人熟知,不过自己一直没有机会了解下这方面东东,最近有时间稍微看了下Mongodb的bson协议,在同事的指导下,整理出来分享给大家。至于BSON的概念我就不赘述了,自己找度娘。
查看文章...
Lucene in action 读书笔记 28 Jul 2014
09年的时候就接触了lucene,可惜一直没有机会在项目中实战,去年终于有机会在项目离使用,可惜由于当时时间紧张,没有好好深入,只是用到什么看什么。最近重新看了下《Lucene In Action》,算是系统的对lucene有个了解,该笔记记录了该书中第一章,主要针对Lucene的基本概念和用法做了描述。
查看文章...
Apache shiro踢出用户和获取所有在线用户 28 Jul 2014
产品要求用户只能在同一个地方登录,如果之前在其他机器或者浏览器上登录,讲之前登录帐号踢出。applicationContext-shiro.xml配置:
在默认的shiro配置上增加如下配置(本文假设你已经使用过apache shiro,并且已经使用shiro成功实现登录功能)
查看文章...
构建高性能web网站 读书笔记 25 Jul 2014
构建高性能web网站读书笔记
目录:分布式缓存,web负载均衡,内容分发和同步,数据库扩展, 性能监控
查看文章...
使用jsoup解析html文档 21 Jul 2014
Jsoup是一款开源的抓取和解析网页的java组件,它可以很方便的对静态html进行解析,也可以方便的根据URL获取动态的页面内容,支持POST和get方式请求,而且支持参数的传递。其设计非常简单易用,毫无学习压力。
查看文章...
你真的已经搞懂javascript了吗 08 Oct 2013
(转载),猛戳查看原文 引原文:昨天在著名前端架构师Baranovskiy的博客中看到一个帖子《So, you think you know JavaScript?》
查看文章...
中小it企业项目团队人员配置管理 07 Jul 2013
(转载),猛戳查看原文 引原文:最近在公司做项目,关于团队管理有了些自己的认识,本想自己写的项目管理的东西,因自感项目管理经验的累积不是很厚,搜索了网上的相关文章,我觉得和我最近的感慨相近。其要领如下:
查看文章...
监控软件之beanshell 14 Mar 2013
监控软件在事件配置公式中使用了BeanShell,那么这玩意儿是啥?能干嘛?为什么在这里用呢?让我们一起来拨开她的外衣,好好瞅瞅吧。
查看文章...
西安 06 Nov 2012
西安行
查看文章...
成都 13 Oct 2012
成都行
查看文章...
济南 12 Oct 2012
济南行
查看文章...
Linux开启telnet 04 Nov 2009
Linux默认没有开启telnet, 首先更改/etc/xinetd.d/telnet文件,有的可能没有该文件,有比如krb5-telnet之类的,那就更改这个文件,如果实在一个跟telnet沾边的文件都没有;可能是没有安装telent服务,就需要拿盘再安装了,或者安装后还没有,就新建一个该文件,文件内容为
查看文章...
Java生成xml数据的一点困惑 27 Oct 2009
由于之前页面用的是ajax请求数据,后来想在页面再添加一个表格数据的时候也打算继续用这种方式:ajax提交后台组装xml数据返回,回调函数中用js解析xml生成表格。困惑来了,组装xml的时候本来我是这么做的:用一个StringBuilder然后一个一个节点在后面追加。最后用PrinterWriter将这个StringBuilder对象输出。写完之后觉得页面比较乱。
查看文章...
C sharp 连接mysql 24 Oct 2009
想用c#做点桌面应用,可是又不想用sqlserver,准备用mysql,找了些资料,先来个简单的连接例子:
首先要下载mysql的的.net驱动,我下的是:mysql-connector-net-5.0.3,下载地址:ftp://gd.tuwien.ac.at/db/mysql/Downloads/Connector-Net/ 这里也可以:http://library.pantek.com/Applications/MySQL/Downloads/Connector-Net/
查看文章...
Itext 生成图文混排的pdf文件 14 Oct 2009
啥也不说,上代码
查看文章...
用amchart的时候遇到一个难题 28 Sep 2009
用amchart的时候遇到一个难题:将数据库里的数据生成xml (mysql5.0)sql脚本
查看文章...
</ul>