构建高性能web网站读书笔记
目录:分布式缓存,web负载均衡,内容分发和同步,数据库扩展, 性能监控
- 分布式缓存
1.1 数据库前端缓存
1.2 使用memcached
- web负载均衡
2.1 http重定向
2.1.1 1,以前经常用到forward和redirect两种方式来进行页面的转发和重定向。 后一种方式主要是为了客户端刷新导致重复提交
2.1.2 2,通过redirect可以起到将请求转发只其他服务器的方式
2.1.3 3,常用的场景,镜像下载,一般下载较大的文件的时候, 主服务器可以根据客户请求信息判断用户地址,然后讲请求转发至距离客户较近的服务器
2.1.4 4,重定向来做负载均衡的性能瓶颈在于,主服务器的吞吐率; 如果单位时间内请求数超出主服务器的承载能力,这种方式就需要改进了
2.1.5 优点:可以通过web程序对调度策略进行灵活的编程实现
2.2 DNS负载均衡
2.2.1 1,通过讲一个域名指向多个ip,实现DNS负载均衡
2.2.2 2,优点是,DNS服务器压力很小(其就是负载均衡服务器), 不存在性能问题,因为一般客户端浏览器会缓存dns记录,并不是每次用户请求用户都需要去让dns服务器解析下域名
2.2.3 3,智能解析:
2.2.4 4,故障转移
2.2.5 5,不足:dns缓存带来更新的延迟,运维人员对其维护不是很方便,调度策略不是很丰富,很多dns服务器都是使用第三方的
2.3 反向代理负载均衡
2.3.1 1,转移和转发
2.3.2 2,按权重分配任务
2.3.3 3,粘滞会话,通过ip_hash配置,将用户的一个会话始终转发值同一个服务器,以避免针对session的缓存数据错乱

2.3.4 3,性能瓶颈:带宽,吞吐量;另外一旦代理服务器出现问题,就玩完
2.3.5 4,适合的场景:后台业务比较负载,需要大量的运算的业务。代理服务器负责请求的转发,后台服务器负责数据运算。
2.3.6 5,主流的反向代理服务器:apache,nginx,lighttpd
2.4 IP负载均衡
2.4.1 DNAT(反响NAT):通过网络地址转换, 可以让内部网络和外部网络通信, 不仅起到负载均衡的目的, 还可以增加服务器的安全性。
1,必须至少有两块网卡, 一个与外部网络联通, 一个与内部网络连通, 网络机构如下:
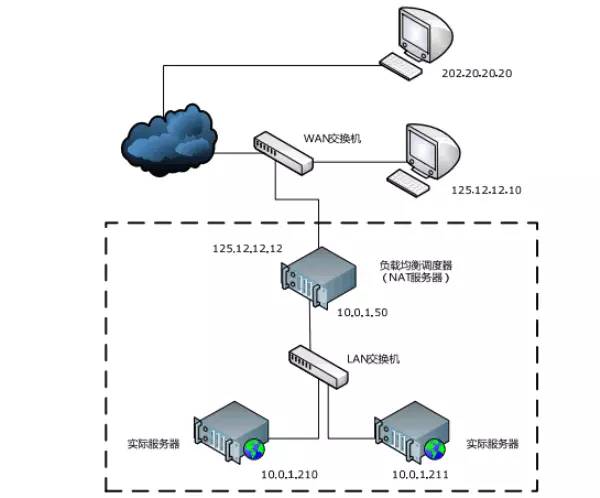
linux的Netfilter模块:对数据包进行过滤,转发
linux提供了iptables命令行工具对Netfilter模块进行编辑。通过该工具可以对转发规则进行配置
Windowsserver版也提供了“路由和远程访问”管理功能,来配置地址转发规则
IPVS:和Netfilter功能类似,不过更专注于IP负载均衡;
2.4.2 性能瓶颈:
作为NAT网管的服务器会成为性能瓶颈
NAT转发数据包的工作发生在内核中, 对于CPU的性能占用基本可以不考虑, 转发能里主要取决于带宽,包括对外和对内带宽。
NAT服务器的带宽必须大于等于内部实际应用服务器的带宽之和, 才能最完美的发挥其转发能力,如图:
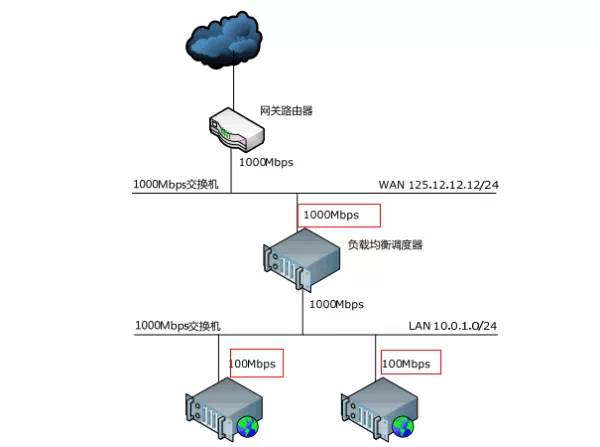
购买专业级的负载均衡服务器也是解决性能瓶颈之一 也可以将DNS负载均衡和IP负载均衡结合起来使用: 前提是有多余的公网ip,可以将域名解析到不同的(廉价实惠的)NAT服务器
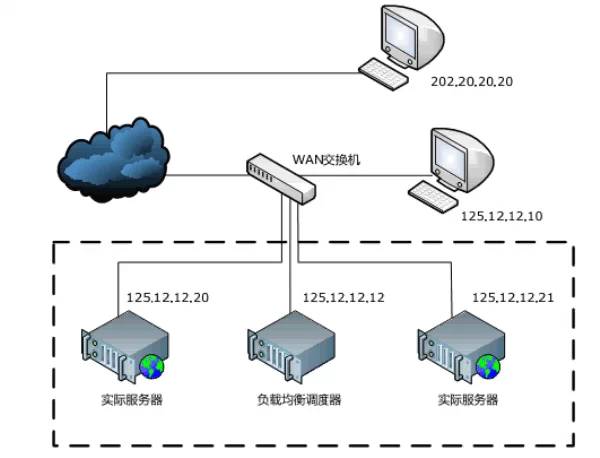
2.5 直接路由(LVS-DR)
2.5.1 机制: 工作在数据链路层,通过修改数据包的目标MAC地址,将数据包直接发送到应用服务器上; 服务器响应不通过调度器,直接返回给用户,应用服务器必须在外网
2.6 IP隧道
2.6.1 机制:同LVS-DR技术基本一致,差别在于,IP隧道技术中,调度服务器和实际服务器可以不在一个wan网段; 主要工作原理是调度服务器讲数据包封装在一个新的IP数据包中发给实际服务器
2.6.2 场景,对于实际服务器部署在不同的地域用该方式比较好
2.6.3 IP Tunning协议是该方式主要使用的协议,一般linux都比较好的实现了该协议,可以方便使用
- 内容分发和同步
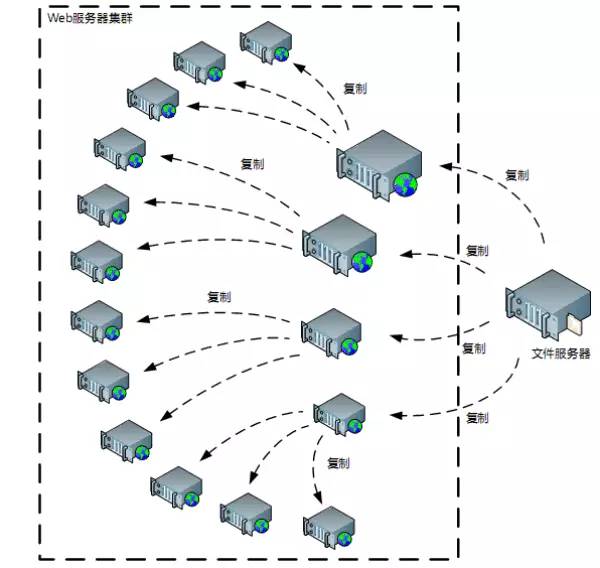
3.1 主动分发
3.1.1 SCP
3.1.2 SFTP
3.1.3 WebDAV
3.1.4 多级分发
3.2 被动分发-同步
3.2.1 rsync
Linux系统实现了该协议,可以配置为计划任务定时从文件发送方的指定目录下,扫描文件并下载。 缺点是,每次都是扫描指定目录的全部内容,如果目录下文件过多,会有性能问题
3.2.2 HashTree
在分发服务器上通过inotify模块监听文件变化状态,文件接收端通过简单的逻辑有选择的获取文件内容
- 数据库扩展
4.1 复制和分离
4.1.1 主从复制
多个从服务器从主服务器复制数据库,除了可以提供多个数据库对外服务外,还可以起到备份数据的作用
4.1.2 读写分离
根据业务需要,比如对于数据库读写要求差别过大; 比如,数据库复杂查询很多,但是写入数据库很少的应用场景, 可以分配一台高性能的服务器作为读服务器,而选择一个相对实惠的低性能服务器作为写服务器 通过主从复制实现读写分离的拓扑图:
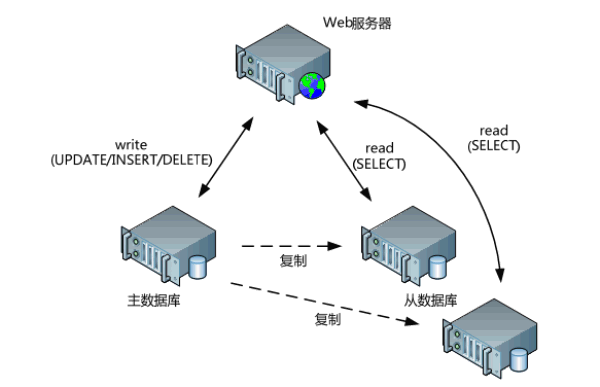
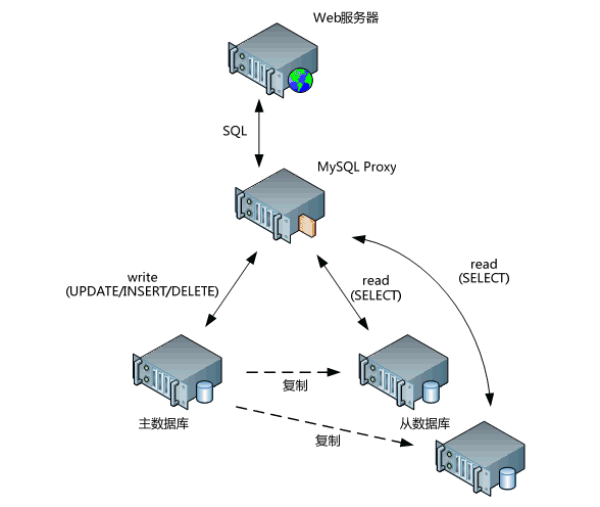
4.1.3 数据库反响代理
比如通过MySQLProxy对应用的数据库操作负载均衡到不同的数据库服务器
4.2 垂直分区
4.2.1 将不同的业务数据放在不同的数据库服务器上 前提是尽量少用联合查询,避免表之间的关联
4.3 水平分区
4.3.1 对于单表数据量过大的情况,可以对分区
4.3.2 a,按时间分区,比如日,月,年
4.3.3 b,按字段分区,比如按照主键进行取模分表
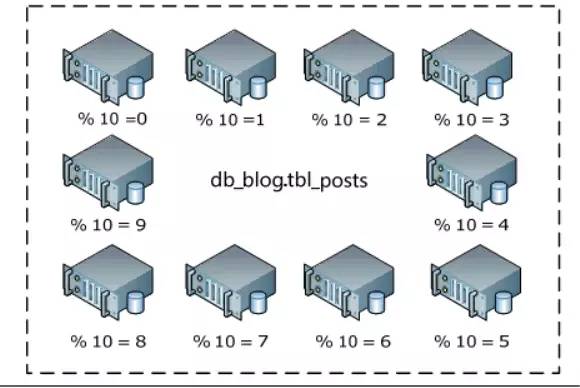
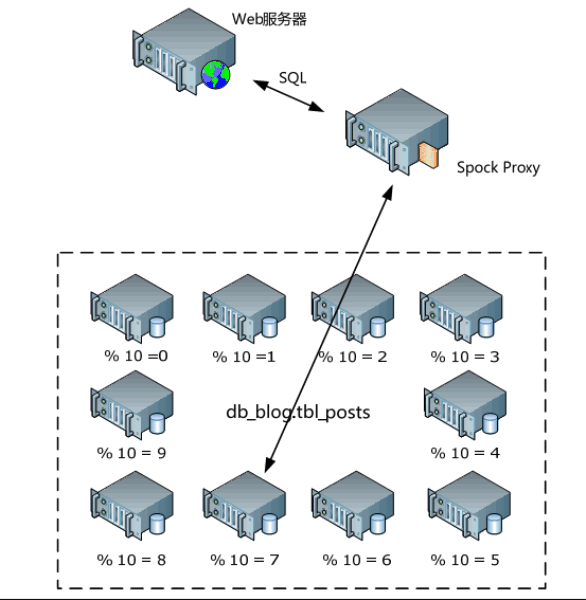
4.4 分区反向代理
- 性能监控
5.1 系统监控:
5.2 应用监控
5.2.1 数据库
5.2.2 web服务